0%
一个简单的脚本,利用切片爬取先知社区的标题、文章链接、作者、作者主页、文章分类、发表时间、评论数,写的很辣鸡,大佬就当个笑话。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| import requests
response = requests.get('https://xz.aliyun.com/?page=1').text
table = response.find('<table class="table topic-list">')
_table = response.find('</table>')
connet = response[table:_table]
c = connet.split('<tr><td>')
for n in range(1, 31):
d = c[n].split(r'<a href="')[1]
authorurl = d.split(r'">')[0] # 作者链接
e = d.split(r'">')[1]
author = e.split(r'</a> /')[0] # 作者
f = c[n].split(r'">')[8]
tags = f.split(r'</a>')[0] # 分类
time = c[n].split(r'/ ')[1][0:10] # 时间
g = c[n].split(r'">')[5]
title = g.split(r'</a>')[0] #标题
h = c[n].split(r'href="')[2]
titleurl = h.split(r'">')[0]
j = c[n].split(r'<span class="pull-right"><span class="badge badge-hollow text-center ">')[1]
number = j.split('</span>')[0]
with open(r"D:\xz.txt", "a", encoding='utf-8') as file: # 在D盘中打开/创建一个名为先知的txt文件
file.write('标题:' + title.strip() + '\n') # 向文件中写入title的字符串(即文章的标题),并换行
file.write('文章链接:' + 'https://xz.aliyun.com' + titleurl + '\n') # 向文件中写入文章的链接,并换行
file.write('作者:' + author + '\n')
file.write('作者主页:' + 'https://xz.aliyun.com' + authorurl + '\n')
file.write('文章分类:' + tags + '\n')
file.write('发表时间:' + time + '\n')
file.write('评论数:' + number + '\n\n')
|
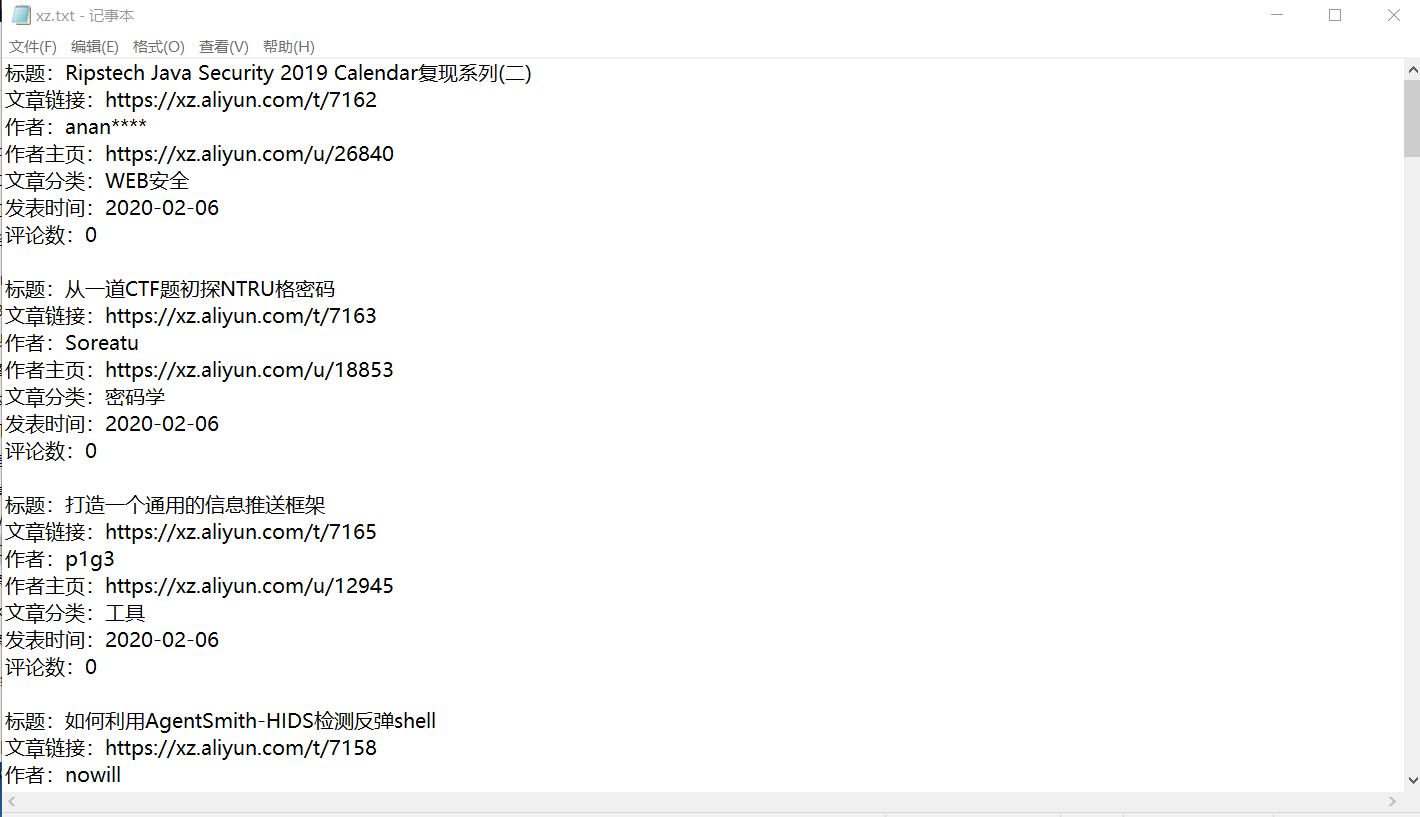
效果